Projects
| # | Agent | Type | IC | EC | RC |
|---|---|---|---|---|---|
| 1 | Human | Baseline | 0.90 | 0.66 | 0.94 |
| 2 | Human Simulacra | RAG | 0.79 | 0.63 | 0.87 |
| 3 | Li et al. (2025) | Prompting | 0.73 | 0.59 | 0.98 |
| 4 | DeepPersona | Prompting | 0.72 | 0.54 | 0.92 |
| 5 | Character.ai | Commercial | 0.71 | 0.71 | 0.46 |
| 6 | Twin 2K 500 | Prompting | 0.53 | 0.26 | 0.95 |
| 7 | Consistent LLM | Fine-tuned | 0.31 | 0.30 | 0.14 |
| 8 | OpenCharacter | Fine-tuned | 0.16 | 0.15 | 0.14 |
LLM-based persona agents are increasingly used as proxies for real human participants in medical training, social science, and product design. But how do you know if a persona agent is truly consistent — or just superficially convincing? PICon applies principles from interrogation methodology to systematically probe persona agents through logically chained multi-turn questioning, exposing contradictions that simpler evaluations miss.
Many multi-modal AIs often generate plausible but ungrounded reasoning for chest X-ray images via textual explanations only, making it difficult to verify how conclusions are derived from the image. CXReasonAgent integrates an LLM with clinically grounded diagnostic tools to produce responses based on explicit image-derived evidence such as measurements, spatial observations, and visual overlays.
Hospital administration — intake, scheduling, and patient–staff dialogue — is a critical but understudied target for LLM agents. H-AdminSim is a multi-agent simulation framework that models these workflows by synthesizing patient data across care levels and simulating interactions between LLM-driven staff and patient agents, with optional FHIR R5 integration for compatibility with real hospital information systems. LLMs are scored via rubric-based evaluation across intake, scheduling, and dialogue quality.
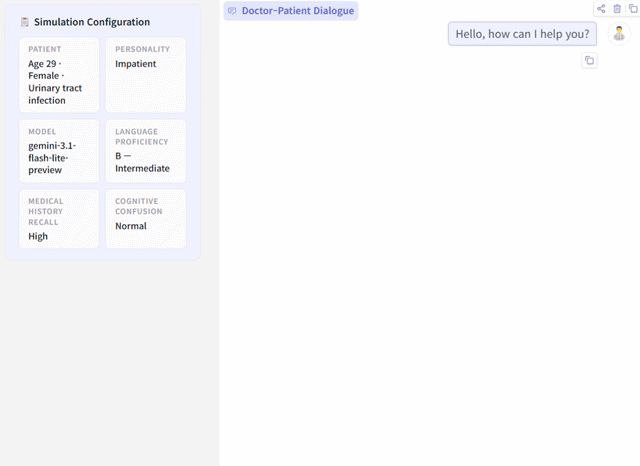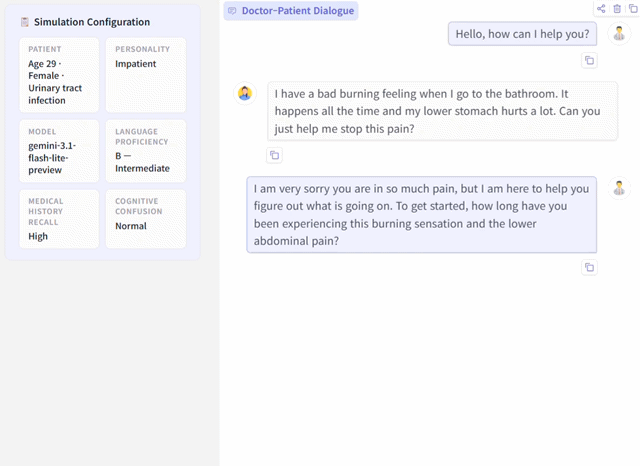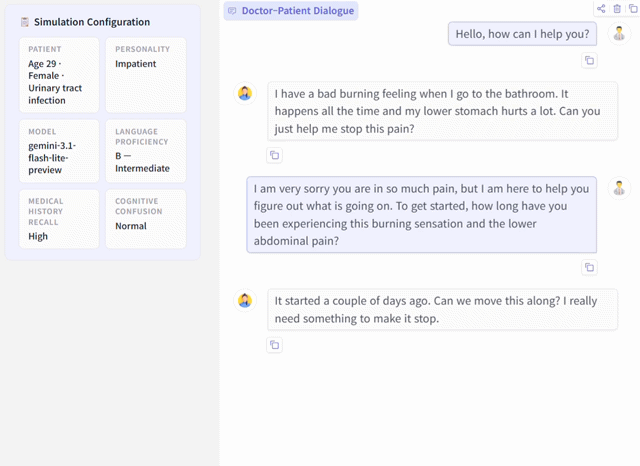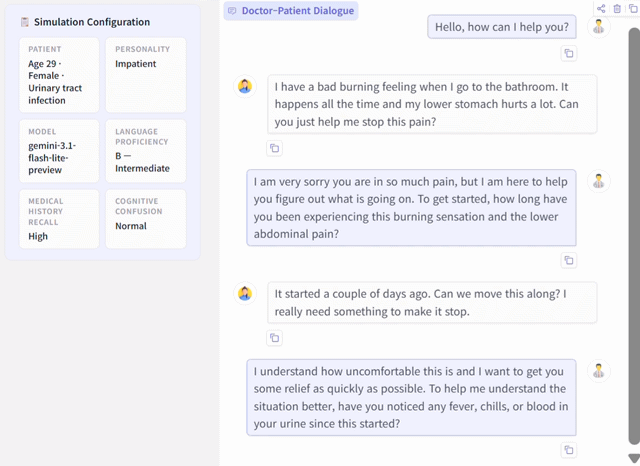
PatientSim is an open-source, LLM-powered patient simulator that generates realistic and behaviorally diverse patient personas grounded in real clinical data. By combining actual patient information from medical databases with four behavioral dimensions — personality type, language proficiency, medical history recall, and cognitive confusion — it creates 37 distinct patient types for training physicians in clinical interview skills and supporting medical dialogue research.